The general m×n system written out at the end of Lesson 3AM already arranges its coefficients aij in m rows and n columns on the page, and its right-hand sides bi in a single column of length m. Up to now those two rectangles were only typographic scaffolding for the equations. Once they are named as objects of their own, every question about existence, uniqueness, and structure of the system becomes a question about them, and the individual unknowns xj drop out of the bookkeeping. The rest of the course is essentially the study of those rectangles.
The Rectangular Array
Definition 36 (Rectangular Matrix)
An m×n matrix over a field F is an ordered array of mn scalars aij∈F, indexed by 1≤i≤m and 1≤j≤n, arranged in m rows and n columns:
The scalar aij is the entry of A at row i and column j, and the pair (m,n) is the size of A. We shorten the display to
A=[aij]i,j=1m,n,orA=[aij]
when the index ranges are clear from context. The set of all m×n matrices over F is written Fm×n; in particular, when F=R we write Rm×n.
The field F is the generic field introduced at the close of Lesson 3AM; unless stated otherwise the default reading F=R remains in force.
Definition 37 (Equality of Matrices)
Matrices A=[aij] and B=[bij] are equal, written A=B, if and only if they have the same size (m,n) and aij=bij for every 1≤i≤m and 1≤j≤n.
The size requirement is not redundant. A 2×3 and a 3×2 matrix with the same multiset of entries are never equal, because the index pairs on either side of the proposed equality do not even match up.
has m=2 equations in n=3 unknowns, so its coefficient table is the 2×3 matrix
A=[111−112]∈R2×3,
while its right-hand sides form the 2×1 column
b=[10]∈R2×1.
The pair (A,b) determines the system: the unknowns x,y,z never appear once the entries have been read off. Row reduction and every later test for existence, uniqueness, and structure will be carried out on (A,b) without rewriting the equations.
Square Matrices and Diagonals
The coefficient matrix of a system is square precisely when the number of equations equals the number of unknowns, the case where geometric intuition in R2 and R3 from the two earlier lessons was sharpest: two non-parallel lines meeting in a point, three generic planes meeting in a point. A dedicated vocabulary for the square case is worth pinning down before we have to exercise it.
Definition 38 (Square Matrix and Its Diagonals)
A matrix A=[aij]∈Fn×n is square, and its common side length n is the order of A. The entries a11,a22,…,ann form the main diagonal of A; the entries a1n,a2,n−1,…,an1 form the secondary diagonal:
with the main diagonal picked out in red and the secondary diagonal in blue.
The main diagonal is where self-interaction sits: in a square system the coefficient aii measures how strongly the ith equation depends on the ith unknown, and the structure of the remainder governs how quickly an elimination schedule can clean that dependence up.
Triangular and Diagonal Matrices
The square systems easiest to solve by hand are those whose coefficient matrix already has half of its off-diagonal entries equal to zero.
Definition 39 (Triangular Matrix)
A square matrix A=[aij]∈Fn×n is upper triangular when aij=0 for every i>j, and lower triangular when aij=0 for every i<j. Schematically,
An upper triangular system is solved by back-substitution: the last row fixes xn, the penultimate row fixes xn−1 once xn is known, and so on up. Lower triangular systems are solved the same way from the top down. The whole apparatus of row reduction, developed from the next lesson on, aims at one of these two shapes.
Definition 40 (Diagonal, Scalar, Identity, and Zero Matrices)
A square matrix A=[aij]∈Fn×n is diagonal when aij=0 for every i=j; equivalently, when it is both upper and lower triangular:
When all those diagonal entries are the same scalar a∈F, the matrix is scalar; the case a=1 is the identity matrixI, and the case a=0 is the square zero matrix0:
A rectangular matrix of any size whose every entry is zero is likewise called a zero matrix.
The hierarchy is cumulative: scalar matrices are a special case of diagonal matrices, which are a special case of both triangular families. The identity I will turn out to behave like the multiplicative 1 in F once matrix multiplication is on the table, and a diagonal system diag(d1,…,dn)x=b is essentially n uncoupled one-variable equations dixi=bi.
Every entry strictly above the main diagonal of M1 is zero, so M1 is lower triangular; the matrix M2 has every off-diagonal entry zero and every diagonal entry equal to 2, so it is scalar, with M2=2I when I is read as the 3×3 identity; and M3 is diagonal but not scalar, because its diagonal entries differ. The main diagonal of M1 is (3,−1,7) and its secondary diagonal is (0,−1,5).
Hermitian and Symmetric Matrices
Here C denotes the complex numbers. If z=a+bi with a,b∈R and i2=−1, then its complex conjugate is z=a−bi.
The next two definitions record an internal symmetry of the entries of a square matrix. Over C the symmetry is combined with conjugation; over R conjugation is invisible and the two families coincide.
Definition 41 (Hermitian Matrix)
A square matrix A=[aij]∈Cn×n is Hermitian, or self-adjoint, when
aji=aijfor every 1≤i,j≤n.
Setting i=j forces aii=aii, so every diagonal entry of a Hermitian matrix is real.
Definition 42 (Symmetric Matrix)
A square matrix A=[aij]∈Fn×n is symmetric when
aji=aijfor every 1≤i,j≤n.
When F=R conjugation acts as the identity, so aji=aij and aji=aij say the same thing: a real matrix is Hermitian precisely when it is symmetric. Over C the Hermitian condition differs from symmetry: it requires real diagonal entries and conjugate off-diagonal pairs rather than equal mirrored entries.
Example 49 (Hermitian Without Being Symmetric)
The 2×2 matrix
H=[1−ii2]∈C2×2
is Hermitian: its diagonal entries 1 and 2 are real, and i=−i gives a21=a12. It is not symmetric, because i=−i. Over R no analogous separation is possible: for a real matrix, matching entries across the diagonal already matches their conjugates, which is why lesson series restricted to R often speak only of symmetric matrices and drop the Hermitian label entirely.
Rows, Columns, and Position Vectors
The thinnest matrices, those with m=1 or n=1, are the column and row arrangements drawn since Lesson 1AM, now relabelled inside the framework of this lesson.
Definition 43 (Row and Column Matrices)
A column matrix of length n is an n×1 matrix
b=b1b2⋮bn∈Fn×1,
and a row matrix of length n is a 1×n matrix
c=[c1c2⋯cn]∈F1×n.
Both are called vectors, or ordered n-tuples, extending the usage of Lesson 1AM and Lesson 2AM to arbitrary length.
Matrix equality refuses to identify a column matrix in Fn×1 with the row matrix in F1×n carrying the same entries, because their sizes disagree. A formal bridge between the two, the transpose, is introduced later in this lesson; until then we keep the column arrangement as the default avatar of a vector, as in every previous lesson of the course.
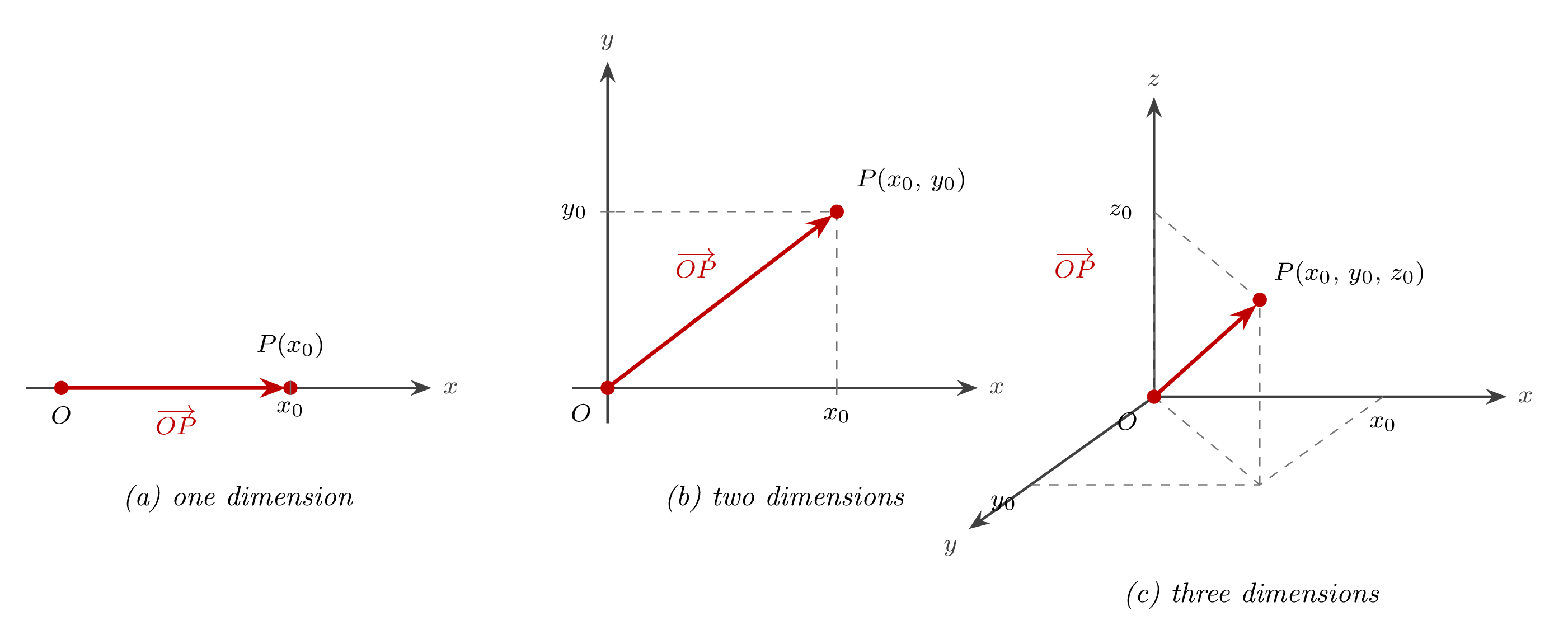
For n=1,2,3 the geometric reading is the one the figure illustrates. A point P in three-dimensional Euclidean space with Cartesian coordinates (x0,y0,z0) is associated with the 3×1 column
x0y0z0∈R3×1,
and this column is exactly the position vector OP fixed to P in Lesson 1PM and extended to R3 in Lesson 2AM. The arrow from the origin to P and the column of its coordinates carry the same content; the two points of view will be used interchangeably. For n≥4 the arrow picture stops being available, but the column matrix still keeps the bookkeeping running, and that is the only reason the higher-dimensional arguments ahead remain tractable.
Length is imported without change. The magnitude ∥b∥ of a real column vector was defined from Pythagoras in Lesson 1AM and inherited by R3 in Lesson 2AM through the iterated-Pythagoras argument; the same Euclidean formula defines ∥b∥ for every b∈Rn×1, no alteration required.
Write down its coefficient matrix A and right-hand side column b, name the field F for which the system lives in Fm×n and Fm×1, and decide which (if any) of the labels “square”, “upper triangular”, “lower triangular”, “diagonal”, “symmetric” apply to A. Justify each rejection by producing an entry that violates the corresponding condition.
Addition and Scalar Multiplication
A vector of length n is a matrix with one row or one column, and its addition and scalar multiplication were fixed entry by entry in Lesson 1AM and inherited by R3 without change in Lesson 2AM. Widening the rectangle from one row or column to m×n requires no new idea: we define addition and scaling on matrices the same way, entry by entry, and the previous geometric readings, parallelogram law and directed rescaling, survive untouched on the thin-matrix cases.
Definition 44 (Matrix Addition)
Let A=[aij] and B=[bij] both lie in Fm×n. Their sum is the m×n matrix
A+B=[aij+bij]i,j=1m,n.
The operation is defined only when A and B have the same size; mismatched sizes have no sum.
Restricted to column or row matrices the formula reproduces the componentwise vector addition of Lesson 1AM, together with the parallelogram-law reading illustrated there. Subtraction is introduced by the same device as in F: the differenceA−B is the unique X∈Fm×n for which X+B=A, namely X=[aij−bij]. The m×n zero matrix 0 is the additive identity: A+0=A and A−0=A for every A∈Fm×n.
Theorem 46 (Algebra of Matrix Addition)
For A,B,C∈Fm×n,
A+B=B+A,(A+B)+C=A+(B+C).
Proof
Every entry of A+B is the scalar aij+bij, and every entry of B+A is bij+aij; these coincide because addition in F is commutative, one of the nine field axioms carried over from R to any F at the close of Lesson 3AM. The same argument applied to (aij+bij)+cij=aij+(bij+cij) handles associativity.
■
Shape is preserved under addition: the sum of two upper (respectively lower) triangular matrices of the same order is upper (respectively lower) triangular, and the sum of two diagonal matrices of the same order is diagonal, since the zero pattern on the relevant side of the main diagonal is carried through the entrywise sum unchanged.
Definition 45 (Scalar Multiplication of a Matrix)
For A=[aij]∈Fm×n and α∈F, the scalar multipleαA is the m×n matrix
αA=[αaij]i,j=1m,n.
We write −A for (−1)A, so that A−B=A+(−B).
Restricted to columns or rows the formula reproduces the scalar multiplication of vectors from Lesson 1AM, and for real α the geometry illustrated there applies unchanged: the length of αa is ∣α∣ times the length of a, with the direction preserved when α>0 and reversed when α<0.
Theorem 47 (Algebra of Scalar Multiplication)
For A,B∈Fm×n and α,β∈F,
0A=0,(α+β)A=αA+βA,α(A+B)=αA+αB,α(βA)=(αβ)A.
Proof
Each identity holds entrywise from a single field axiom applied to the scalars α,β,aij,bij: annihilation 0⋅aij=0 for the first, distributivity of F for the second and third, and associativity of multiplication in F for the fourth.
■
Example 50 (Adding and Scaling Matrices)
Let
A=[23−1401],B=[1021−35].
Then
A+B=[3315−36],2A−3B=[16−859−13],
while pairing A with a 3×2 matrix would leave A+⋅ undefined, the sizes not agreeing.
Matrix Multiplication
The m×n system packaged at the close of Lesson 3AM writes the ith equation as
ai1x1+ai2x2+⋯+ainxn=k=1∑naikxk=bi,
a scalar entirely determined by the ith row of the coefficient matrix A and the column x of unknowns. Collecting all m scalars into a single column recovers the right-hand side b. Any operation that packages A and x into a product Ax must reproduce exactly this “row into column” pairing, and the definition below is the unique extension of that rule to arbitrary conformable matrices.
Definition 46 (Matrix Product)
Let A=[aij]∈Fm×l and B=[bij]∈Fl×n; here the column count of A and the row count of B agree, and A,B are called conformable in this order. Their product is the m×n matrix AB=[cij] with entries
When the column count of A does not match the row count of B, the product AB is not defined.
Remark (Row-Into-Column as a Special Case)
If
r=[a1a2⋯al]∈F1×l,c=b1b2⋮bl∈Fl×1,
then rc is a 1×1 matrix whose single entry is
a1b1+a2b2+⋯+albl.
Over R this is exactly the familiar dot product of the corresponding vectors.
Computationally, cij is obtained by pairing the ith row of A with the jth column of B and summing the products one index at a time. For the system of Lesson 3AM the product Ax is precisely the column of left-hand sides of the equations, so the entire m×n system collapses to the single identity
Ax=b.
This reformulation is the whole reason matrix multiplication is fixed the way it is. Every existence, uniqueness, and structure question from Lesson 3AM is now a question about a single equation in the matrix variable x.
Example 51 (A First Row-Into-Column Product)
Let
A=[20−1301],B=321010.
The column count of A and the row count of B both equal 3, so AB lies in R2×2. Pairing each row of A with each column of B,
The reverse product BA is also conformable, since the column count of B and the row count of A both equal 2, but BA lands in R3×3: the two products live in different spaces, and the question of whether AB=BA is, here, meaningless.
Theorem 48 (The Identity Acts as a Unit)
Let Im,In denote the identity matrices of orders m and n. For every A∈Fm×n,
ImA=A,AIn=A.
In particular, IA=AI=A whenever A is square of the same order as I.
Proof
The (i,k) entry of Im is 1 when i=k and 0 otherwise. Therefore
(ImA)ij=k=1∑m(Im)ikakj=aij,
since only the term k=i survives. The argument for AIn is identical: in
(AIn)ij=k=1∑naik(In)kj,
only the term k=j survives.
■
Theorem 49 (Distributive and Associative Laws)
For matrices of sizes such that every product and sum below is defined,
A(B+C)=AB+AC,(B+C)D=BD+CD,A(BC)=(AB)C.
Proof
Fix A∈Fm×l and B,C∈Fl×n. For the left distributive law,
the middle equality swapping the order of the two finite sums, legitimate in any field.
■
Matrix multiplication loses several properties that scalar multiplication enjoyed. The failures are cumulative, and the sharpest of them is the following.
Theorem 50 (Matrix Multiplication is Not Commutative)
For every n≥2, there exist square matrices A,B∈Fn×n with AB=BA.
Proof
Take n=2 and
A=[2010],B=[1−100].
Direct computation gives
AB=[1000],BA=[2−21−1],
which disagree at every entry outside the (1,1) position. Padding A and B with zeros embeds the same witness into Fn×n for every n≥2.
■
Remark
Two further failures are worth recording. The product of two non-zero matrices may vanish: the choice
A=[1000],B=[0001]
gives AB=0, so non-zero matrices can multiply to zero. Cancellation fails too: if AB=AC with A=0, it need not follow that B=C. With the same A as above, any two matrices B,C that agree on their first row but differ on their second satisfy AB=AC, because the zero second row of A annihilates every disagreement in the second row of B and C.
Having a well-behaved notion of product, and an identity I that acts as a unit, permits iterating the operation.
Definition 47 (Powers of a Square Matrix)
Let A∈Fn×n be square. For every positive integer p set
Ap=p factorsAA⋯A,
and define A0=I and A1=A.
Theorem 51 (Exponent Laws for Matrix Powers)
For A∈Fn×n and non-negative integers p,q,
ApAq=Ap+q,(Ap)q=Apq.
Remark (A Word on Induction)
A few arguments in this lesson depend on a positive integer parameter, such as an exponent p. In such cases we will sometimes use mathematical induction, an important proof technique that we will study properly later in MCEA and again in MA1B.
For now, the version we need is simple:
first verify the statement at an initial value, usually p=0 or p=1;
then show that if the statement holds for one value p=k, it must also hold for the next value p=k+1.
Once these two steps are established, the statement follows for every integer from the starting point onward. In the present lesson we use induction only in this basic step-by-step form.
Proof
Fix p and induct on q for the first identity. The base case q=0 reads ApI=Ap, which is the identity acting as a unit. For the inductive step,
ApAq+1=Ap(AqA)=(ApAq)A=Ap+qA=A(p+q)+1,
by associativity of matrix multiplication and the inductive hypothesis. Induct on q for the second identity. The base case q=0 reads (Ap)0=I=A0=Ap⋅0. For the inductive step,
(Ap)q+1=(Ap)qAp=ApqAp=Apq+p=Ap(q+1),
by the inductive hypothesis and the first exponent law.
■
Example 52 (Cubing a Small Upper-Triangular Matrix)
The upper-triangular shape of A persists through every power. For p≥1 and indices i>j, the entry (Ap)ij is a sum of products aik1ak1k2⋯akp−1j; a non-zero such product would force i≤k1≤k2≤⋯≤kp−1≤j, which contradicts i>j.
and write it in the single-line form Ax=b by identifying the coefficient matrix A and the right-hand side column b. Produce any particular column x0∈R3×1 that satisfies the system and verify by direct row-into-column multiplication that Ax0=b.
Problem 33
Let a∈Fm×1 be a column matrix and c∈F1×n a row matrix. Show that the product ac, in this order, is defined and lies in Fm×n, and write out the (i,j) entry of ac in terms of the components of a and c. This matrix is called an outer product of a and c.
Problem 34
Let A∈Fm×l have columns a1,a2,…,al∈Fm×1, and let B∈Fl×n have rows r1,r2,…,rl∈F1×n. Using the outer-product construction of the previous problem, prove the column-row decomposition
AB=k=1∑lakrk,
where each summand akrk is an m×n outer product. Compare this expression with the row-into-column formula that defines AB directly, and convince yourself that the two points of view compute the same entries.
Special Kinds of Matrices Related to Multiplication
The failure of commutativity in the earlier noncommutativity theorem is the source of most of the subtlety in matrix algebra, so it pays to name the cases where commutation is restored and the shapes whose self-multiplication behaves in an unusually rigid way. Four labels below cover the patterns that will reappear throughout the rest of the course.
Commuting Matrices
Definition 48 (Commuting Matrices)
Square matrices A,B∈Fn×ncommute when AB=BA. The difference [A,B]=AB−BA is the commutator of A and B, and A and B commute exactly when [A,B]=0.
Commutation is the exception, not the rule; the earlier noncommutativity theorem already supplied a 2×2 counterexample, and every computation with two generic matrices should start from the assumption that order matters. The results below are the standard reasons commutation is recovered in practice.
Theorem 52
For any A∈Fn×n and any scalar λ∈F, the matrix λIn commutes with A:
A(λIn)=λA=(λIn)A.
Proof
The (i,j) entry of A(λIn) is
k=1∑naik(λIn)kj,
and all terms vanish except the one with k=j, because the only non-zero entry in column j of λIn is the diagonal entry λ. Hence (A(λIn))ij=λaij. Likewise,
((λIn)A)ij=k=1∑n(λIn)ikakj,
and all terms vanish except the one with k=i, so ((λIn)A)ij=λaij. Both therefore agree with the (i,j) entry of λA.
■
Problem 35
Show that a matrix S∈Fn×n commutes with every square matrix in Fn×n if and only if S is a scalar matrix aIn for some a∈F.
Theorem 53 (Diagonal Matrices Commute)
If
D=diag(d1,d2,…,dn),E=diag(e1,e2,…,en),
then
DE=ED=diag(d1e1,d2e2,…,dnen).
Proof
Since every off-diagonal entry of D and E is zero, the product of row i with column j vanishes when i=j, so both DE and ED are diagonal. On the diagonal,
(DE)ii=diei=eidi=(ED)ii,
because multiplication in F is commutative.
■
Theorem 54 (Commuting with a Diagonal Matrix of Distinct Entries)
Let
D=diag(d1,d2,…,dn)∈Fn×n
with di=dj whenever i=j. If A=[aij]∈Fn×n satisfies AD=DA, then A is diagonal.
Proof
The (i,j) entry of AD is aijdj, while the (i,j) entry of DA is diaij. Hence
aijdj=diaij,
so
(dj−di)aij=0.
If i=j, then dj−di=0, and since we are working in a field this forces aij=0. Thus every off-diagonal entry of A is zero, so A is diagonal.
■
Theorem 55
If A,B∈Fn×n commute, then ApB=BAp for every p≥0, and more generally ApBq=BqAp for every p,q≥0.
Proof
Fix B and induct on p. The base p=0 reads IB=B=BI. For the step,
Ap+1B=A(ApB)=A(BAp)=(AB)Ap=(BA)Ap=BAp+1,
using the inductive hypothesis at the second equality and commutation at the fourth. A symmetric induction on q gives ABq=BqA, and combining the two yields ApBq=BqAp.
■
Theorem 56 (The Commutant Is Closed)
Fix A∈Fn×n and let C(A)={X∈Fn×n:AX=XA} be its commutant. If X,Y∈C(A) and α∈F, then X+Y, αX, and XY all lie in C(A).
Proof
From AX=XA and AY=YA: A(X+Y)=AX+AY=XA+YA=(X+Y)A; A(αX)=αAX=αXA=(αX)A; and A(XY)=(AX)Y=(XA)Y=X(AY)=X(YA)=(XY)A. The first two computations use distributivity and scalar compatibility, and the last uses associativity of matrix multiplication together with the commutation hypotheses.
■
Example 53 (Commutant of a Diagonal Matrix)
Find every B∈R2×2 that commutes with
A=[2003].
Write B=[prqs]. Then
AB=[2p3r2q3s],BA=[2p2r3q3s],
so AB=BA forces 2q=3q and 3r=2r, that is q=r=0, while p,s remain free. The commutant is
C(A)={[p00s]:p,s∈R}.
Were the two diagonal entries of A equal, the calculation would instead return every 2×2 matrix, in agreement with the scalar-matrix commuting theorem above.
Problem 36
Determine every B∈R2×2 that commutes with
A=[1011],
and describe what changes, compared with the diagonal example just above, once the off-diagonal entry is introduced.
Idempotent Matrices
A matrix whose square returns itself is the algebraic shape every projection in the course will turn out to have.
Definition 49 (Idempotent Matrix)
A square matrix A∈Fn×n is idempotent when A2=A. Both In and 0n are idempotent by inspection, and induction on p gives Ap=A for every p≥1.
Example 54 (A Non-Trivial Idempotent)
The matrix
A=1002002−11
satisfies A2=A. The rows of A2 are read off row-into-column: row one of A times the columns of A gives (1,2,1⋅2+2⋅(−1)+2⋅1)=(1,2,2), row two gives (0,0,0⋅2+0⋅(−1)+(−1)⋅1)=(0,0,−1), and row three gives (0,0,0⋅2+0⋅(−1)+1⋅1)=(0,0,1). Stacking these reproduces A. The matrix is neither 0 nor I, so idempotence is genuinely richer than the two trivial endpoints.
Theorem 57 (The Complementary Idempotent)
If A∈Fn×n is idempotent, so is In−A, and the two matrices annihilate each other:
A(In−A)=(In−A)A=0.
Proof
Using the unit and distributive laws established earlier,
(I−A)2=I−2A+A2=I−2A+A=I−A,
so I−A is idempotent. For the orthogonality, A(I−A)=A−A2=A−A=0, and (I−A)A=A−A2=0 by the same cancellation.
■
Example 55 (A Projection and Its Complement)
Let
P=[1000].
Then P2=P, so P is idempotent. Its complementary idempotent is
I2−P=[0001],
and indeed
P(I2−P)=(I2−P)P=0.
These two matrices project onto the coordinate axes separately: left multiplication by P keeps the first coordinate and kills the second, while left multiplication by I2−P does the opposite.
Problem 37
Let A,B∈Fn×n be idempotent and commute. Prove that AB is idempotent, and exhibit two idempotents in R2×2 that do not commute and whose product is not idempotent, showing that the hypothesis AB=BA is load-bearing rather than cosmetic.
Problem 38
Classify all idempotent matrices in F2×2. In other words, determine all
A=[acbd]
for which A2=A.
Nilpotent Matrices
Opposite to idempotents, for which repeated multiplication stabilises, are matrices whose repeated multiplication annihilates them outright.
Definition 50 (Nilpotent Matrix)
A square matrix A∈Fn×n is nilpotent when there is an integer p≥1 with Ap=0. The smallest such p is the index of nilpotence of A.
Example 56 (Strictly Upper-Triangular Nilpotent)
The matrix
N=000100010
satisfies
N2=000000100,N3=03,
so N is nilpotent with index 3. Each successive power pushes the non-zero band one step further above the main diagonal until it exits the matrix.
Theorem 58 (Strictly Triangular Matrices Are Nilpotent)
Every strictly upper-triangular A∈Fn×n, meaning aij=0 whenever i≥j, satisfies An=0.
Proof
We prove by induction on p≥1 that
(Ap)ij=0whenever j−i<p.
For p=1 this is exactly the assumption that A is strictly upper-triangular: if j−i<1, then j≤i, so aij=0.
Now assume the claim for some p. Then
(Ap+1)ij=k=1∑n(Ap)ikakj.
For a term (Ap)ikakj to be non-zero, the induction hypothesis forces k−i≥p, and strict upper-triangularity forces j−k≥1. Adding gives
j−i=(j−k)+(k−i)≥1+p=p+1.
So if j−i<p+1, every term in the sum is zero, and hence (Ap+1)ij=0. This proves the induction step.
Finally, in an n×n matrix we always have j−i≤n−1. Therefore when p=n the inequality j−i<n holds for every pair (i,j), so every entry of An is zero. Hence An=0.
The same argument, with the inequalities reversed, handles the strictly lower-triangular case.
■
Problem 39
Show that if A∈Fn×n is nilpotent with Ap=0, then
(In−A)(In+A+A2+⋯+Ap−1)=In.
Deduce that a nilpotent matrix can never equal In, and exhibit a non-zero B∈R2×2 with B2=0 to confirm that the nilpotent class is non-empty beyond the zero matrix.
Problem 40
Classify all nilpotent matrices in F2×2. Determine separately which ones have index of nilpotence 1 and which have index of nilpotence 2.
Involutory Matrices
Definition 51 (Involutory Matrix)
A square matrix A∈Fn×n is involutory when A2=In. Geometrically, multiplication by A is its own undoing; algebraically, A will turn out to be its own inverse once the inverse is defined in a later lesson.
Example 57 (The Swap Matrix Is Involutory)
The matrix
J=[0110]
has
J2=[0⋅0+1⋅11⋅0+0⋅10⋅1+1⋅01⋅1+0⋅0]=[1001]=I2,
so J is involutory. Acting on a column by left multiplication, J swaps the two entries, and performing the swap twice returns the original column.
Theorem 59 (Powers of an Involutory Matrix)
If A∈Fn×n is involutory, then A2k=In and A2k+1=A for every k≥0.
Proof
Induct on k, with A0=I and A1=A as bases. For the even step, A2(k+1)=A2kA2=I⋅I=I, and for the odd step, A2(k+1)+1=A2k+1A2=A⋅I=A, using A2=I at each closure.
■
Theorem 60 (Idempotent Splitting of an Involution)
Let A∈Fn×n be involutory and suppose 21∈F, which holds for F=R and F=C. The matrices
P+=21(In+A),P−=21(In−A)
are idempotent and satisfy P++P−=In, P+−P−=A, and P+P−=P−P+=0.
and the symmetric calculation gives P−2=P−. The sum and difference are by direct expansion, and
P+P−=41(I+A)(I−A)=41(I−A2)=0,
with P−P+=0 by the same cancellation.
■
Example 58 (A Reflection Splits into Two Projections)
Take
A=[100−1].
Then A2=I2, so A is involutory. The associated idempotents are
P+=21(I2+A)=[1000],P−=21(I2−A)=[0001].
So this involution is exactly the difference of two complementary coordinate projections:
A=P+−P−.
Geometrically, A fixes the x-axis and flips the sign on the y-axis.
Remark
An involution can also be characterized by the factorization
A2=In⟺(In−A)(In+A)=0.
Indeed,
(In−A)(In+A)=In+A−A−A2=In−A2,
since In commutes with A. So either condition is exactly the statement In−A2=0.
Problem 41
Verify that
A=[4−53−4]
is involutory, and write down the idempotents P±=21(I2±A) from the idempotent-splitting theorem above for this A.
Problem 42
For any real angle θ, show that
A=[cosθsinθsinθ−cosθ]
is involutory. Reminder:
cos2θ+sin2θ=1.
Problem 43
Let Jn be the n×n matrix with 1 in every position on the secondary diagonal and 0 elsewhere. Show that Jn is involutory, and conclude that −Jn is also involutory.
Problem 44
Prove that if A,B∈Fn×n are involutory and commute, then AB is involutory. Exhibit a 2×2 example showing that the conclusion fails once commutation is dropped.
Problem 45
Assume 21∈F, for example F=R or C. Classify all involutory matrices in F2×2. That is, determine all
A=[acbd]
for which A2=I2.
Transpose and Conjugate Transpose
The previous section left one asymmetry untouched: a column of length n and a row carrying the same entries are genuinely distinct objects in Fn×1 and F1×n because their sizes differ. The transpose is the explicit bridge between the two, and upgraded to complex matrices it becomes the conjugate transpose, the operation that the Hermitian and symmetric conditions introduced earlier in this lesson were secretly measuring.
Definition 52 (Transpose)
The transpose of A=[aij]∈Fm×n is the n×m matrix
A⊤=[aji]i,j=1n,m
obtained by swapping rows and columns: the (i,j) entry of A⊤ is the (j,i) entry of A.
Thus, if
Two readings of the transpose are worth keeping side by side. The rows of A⊤, read left to right, are the columns of A, read top to bottom; and the columns of A⊤ are the rows of A. Geometrically the operation is a reflection of the rectangle across its main diagonal.
The symmetric condition introduced earlier asks aji=aij for every i,j, which is precisely A⊤=A, so a matrix is symmetric if and only if it equals its own transpose. The Hermitian condition aji=aij mixes transposition with conjugation, and it is restated cleanly only after the conjugate transpose is defined below.
Example 59 (Transposes of Small Matrices)
For
A=[142536],b=1−23,
direct reading gives
A⊤=123456∈R3×2,b⊤=[1−23]∈R1×3.
The transpose of a column is the row carrying the same entries, fulfilling the bridge promised in the earlier discussion of rows and columns.
Theorem 61 (Transpose Is an Involution)
For every A∈Fm×n,
(A⊤)⊤=A.
Proof
The (i,j) entry of A⊤ is aji, so the (i,j) entry of (A⊤)⊤ is aij, which is the (i,j) entry of A.
■
Theorem 62 (Transpose of Sum and Scalar Multiple)
For A,B∈Fm×n and α∈F,
(A+B)⊤=A⊤+B⊤,(αA)⊤=αA⊤.
Proof
The (i,j) entry of (A+B)⊤ is (A+B)ji=aji+bji, which is the (i,j) entry of A⊤+B⊤. The (i,j) entry of (αA)⊤ is (αA)ji=αaji, which is the (i,j) entry of αA⊤.
■
Problem 46
If A,B∈Fn×n are symmetric, show that A+B is symmetric.
Theorem 63 (Transpose Reverses Products)
For A∈Fm×l and B∈Fl×n,
(AB)⊤=B⊤A⊤.
More generally, for matrices A1,A2,…,Ak whose sizes make the product A1A2⋯Ak defined,
(A1A2⋯Ak)⊤=Ak⊤⋯A2⊤A1⊤.
Proof
The (i,j) entry of (AB)⊤ is (AB)ji=∑k=1lajkbki, while the (i,j) entry of B⊤A⊤ is
k=1∑l(B⊤)ik(A⊤)kj=k=1∑lbkiajk,
and the two sums agree termwise by commutativity of multiplication in F. The k-fold identity follows by induction on k, using the two-fold version together with the associativity of matrix multiplication established earlier.
■
Example 60 (Transposing a Product)
Let
A=[1−12304],B=2051−12.
Then
AB=[218−14],so(AB)⊤=[2−1184].
On the other hand,
B⊤=[210−152],A⊤=120−134,
and direct multiplication gives
B⊤A⊤=[2−1184]=(AB)⊤.
The order reversal is visible in the calculation: the transpose does not preserve the order of the factors.
Skew-Symmetric Matrices
Definition 53 (Skew-Symmetric Matrix)
A square matrix A∈Fn×n is skew-symmetric when A⊤=−A, equivalently aji=−aij for every 1≤i,j≤n. Setting i=j gives 2aii=0, so whenever 21∈F every diagonal entry of a skew-symmetric matrix is zero.
Example 61 (A Skew-Symmetric Matrix)
The matrix
S=0−2320−5−350∈R3×3
is skew-symmetric: its diagonal is zero, and reflecting each off-diagonal entry across the main diagonal negates it.
Problem 47
Let A∈Fn×n. Show that the matrices
AA⊤,A⊤A,A⊤+A
are symmetric, and that
A−A⊤
is skew-symmetric.
Theorem 64 (Symmetric-Skew Decomposition)
Assume 21∈F. Every A∈Fn×n admits a unique decomposition
A=S+K,S⊤=S,K⊤=−K,
with S symmetric and K skew-symmetric, given by
S=21(A+A⊤),K=21(A−A⊤).
Proof
Existence. Using the transpose involution and the transpose sum rule,
S⊤=21(A⊤+A)=S,K⊤=21(A⊤−A)=−K,
and S+K=21(A+A⊤)+21(A−A⊤)=A.
Uniqueness. Suppose A=S′+K′ with S′ symmetric and K′ skew-symmetric. Transposing gives A⊤=S′−K′, and solving the two equations for S′ and K′ returns the formulas above, forcing (S′,K′)=(S,K).
■
Problem 48
For
A=10734−1−252,
compute the symmetric matrix
S=21(A+A⊤)
and the skew-symmetric matrix
K=21(A−A⊤),
and verify directly that A=S+K.
Complex Conjugate and Conjugate Transpose
Over C the transpose by itself is not quite the right operation: the Hermitian condition introduced earlier mixes transposition with complex conjugation, and the pair needs both halves introduced explicitly before it can be used cleanly.
Definition 54 (Conjugate of a Matrix)
For A=[aij]∈Cm×n the conjugateA is the m×n matrix whose (i,j) entry is aij. Conjugation is the identity on Rm×n, since real scalars are fixed by conjugation in C.
Definition 55 (Conjugate Transpose)
For A∈Cm×n the conjugate transpose, written A∗ (also AH in some texts), is the n×m matrix
Over R conjugation is trivial, so A∗ collapses to A⊤.
The Hermitian condition introduced earlier now reads A∗=A: a matrix is Hermitian precisely when it equals its own conjugate transpose, and over R this reduces further to A⊤=A, the symmetric condition of the previous subsection.
Remark
The 1×1 complex matrices are just the complex numbers in matrix clothing:
[z]⟷z∈C.
Under this identification, the Hermitian condition becomes
[z]∗=[z]⟺z=z,
so the 1×1 Hermitian matrices are exactly the real numbers.
Example 62 (Conjugate Transpose of a Complex Matrix)
For
A=[1+i−3i24−i]∈C2×2,
transposing then conjugating gives
A⊤=[1+i2−3i4−i],A∗=[1−i23i4+i].
Conjugating first and then transposing produces the same result, illustrating the commutativity of the two operations built into the definition of conjugate transpose.
Theorem 65 (Conjugate Transpose Is an Involution)
For every A∈Cm×n,
(A∗)∗=A.
Proof
The (i,j) entry of A∗ is aji, so the (i,j) entry of (A∗)∗ is aij=aij, using that conjugation in C is involutive.
■
Theorem 66 (Conjugate Transpose of Sum and Scalar Multiple)
For A,B∈Cm×n and α∈C,
(A+B)∗=A∗+B∗,(αA)∗=αA∗.
Proof
Entrywise, ((A+B)∗)ij=aji+bji=aji+bji, matching A∗+B∗. For the scalar, ((αA)∗)ij=αaji=αaji, matching αA∗. The appearance of α in place of α is the genuinely new feature once conjugation joins the transpose.
Thus conjugation commutes with transposition and respects matrix products because it respects sums and products of scalars in C. The k-fold identity is by induction on k.
■
Theorem 68 (Hermitian Combinations from a Complex Matrix)
For every A∈Cn×n, the four matrices
A+A∗,i(A−A∗),AA∗,A∗A
are all Hermitian.
Proof
Use the involution rule for ∗ together with the sum, scalar, and product rules above. First, (A+A∗)∗=A∗+(A∗)∗=A∗+A. Second, (i(A−A∗))∗=i(A−A∗)∗=−i(A∗−A)=i(A−A∗). For the last two, (AA∗)∗=(A∗)∗A∗=AA∗, and the same argument with the roles of A and A∗ swapped handles A∗A.
■
Example 63 (Hermitian Combinations in Practice)
Let
A=[1+i−3i24−i].
From the earlier computation,
A∗=[1−i23i4+i].
Then
A+A∗=[22−3i2+3i8],i(A−A∗)=[−23−2i3+2i2].
Both are Hermitian: each equals its own conjugate transpose. The first captures the Hermitian part of A, and the second captures the Hermitian matrix obtained from its skew-Hermitian part by multiplication by i.
Skew-Hermitian Matrices
Definition 56 (Skew-Hermitian Matrix)
A square matrix A∈Cn×n is skew-Hermitian when A∗=−A, equivalently aji=−aij for every 1≤i,j≤n. Setting i=j forces aii=−aii, so every diagonal entry of a skew-Hermitian matrix is purely imaginary.
Example 64 (A Skew-Hermitian Matrix)
The matrix
K=[i−2+i2+i−3i]∈C2×2
is skew-Hermitian: the diagonal entries i and −3i are purely imaginary, and a21=−2+i=−2+i=−a12. Equivalently, iK is Hermitian, since (iK)∗=iK∗=−i(−K)=iK. Multiplication by i therefore exchanges the Hermitian and skew-Hermitian classes.
Example 65 (A Tiny Skew-Hermitian Check)
The matrix
[iiii]
is skew-Hermitian because
[iiii]∗=[−i−i−i−i]=−[iiii].
This is the smallest possible example in which every entry is the same and the whole matrix is still skew-Hermitian.
Theorem 69 (Hermitian-Skew Decomposition)
Every A∈Cn×n admits a unique decomposition
A=H+K,H∗=H,K∗=−K,
with H Hermitian and K skew-Hermitian, given by
H=21(A+A∗),K=21(A−A∗).
Proof
Existence. By the sum and scalar rule for conjugate transpose, H∗=21(A∗+A)=H and K∗=21(A∗−A)=−K, while H+K=A by direct expansion.
Uniqueness. If A=H′+K′ with H′ Hermitian and K′ skew-Hermitian, applying ∗ gives A∗=H′−K′, and solving the pair of equations returns the formulas above, so (H′,K′)=(H,K).
■
Remark
Equivalently, every complex square matrix can be written uniquely in the form
A=H1+iH2,
where both H1 and H2 are Hermitian. Indeed, taking
H1=21(A+A∗),H2=2i1(A−A∗)
gives Hermitian matrices H1,H2 with A=H1+iH2.
Problem 49
Let
A=[1+i4+i2−3i−2i].
Compute A∗ and then form
H=21(A+A∗),K=21(A−A∗).
Verify directly that H is Hermitian, K is skew-Hermitian, and A=H+K.